
An interesting question was recently posed to Coreform and I thought the solution might be interesting, if not useful, to others.
Application
Immersed CFD simulation with a bounding box background grid and a multi-volume body that represents the physical domain.
Request:
Given a hex-meshed volume that envelops a multi-volume body, write a Python script that finds the hexes whose centroids are located inside the multi-volume body. Should have good performance for at least 20E6 hexes – preferably a run-time of a few minutes for this element count.
First attempt:
The person who submitted this request had written a working script, but it wasn’t very performant. They asked us to take a look at their script to see if we could improve upon it. Here’s the original script:
## Helper function
def create_block_1(v1):
cc = "block 1 add hex {0}"
cubit.silent_cmd (cc.format(v1))
## Script body
### Test geometry
cubit.cmd('reset')
cubit.cmd('create brick x 10')
cubit.cmd('create Cylinder height 3 radius 3 ')
cubit.cmd('mesh Volume 1')
cubit.cmd('refine hex all numsplit 1 bias 1.0 depth 1 ') # Refines to 27E3 elements
# cubit.cmd('refine hex all numsplit 2 bias 1.0 depth 1 ') # Refines to 729E3 elements
bc_vol = 2
mesh_vol = 1
cell_list = cubit.get_volume_hexes(mesh_vol)
for c_id in cell_list:
cx=cy=cz=0
count = 0
for n_id in cubit.get_connectivity("hex", c_id):
nc=cubit.get_nodal_coordinates(n_id) # Note-1
cx = cx+ nc[0]
cy = cy+ nc[1]
cz = cz+ nc[2]
count +=1
cxc=cx/count
cyc=cy/count
czc=cz/count
# Note-3
if cubit.body(bc_vol).point_containment([cxc,cyc,czc]):
create_block_1(c_id) # Note-2
else:
pass
cubit.cmd('draw block 1')
The problem with this script is that it took nearly a minute to process only 27K elements and a very long-time (about a day) when processing 729K elements. I’ve included a few comments formatted like: Note-1 to talk about further.
Note-1:
Notice here that since most nodes are shared by more than one element, that we will end up querying the coordinates for each node multiple times. This isn’t a huge issue for small meshes, but could potentially be an issue for larger meshes. Let’s “future-proof” this by creating an array of node coordinates up-front:
def create_nodal_coordinates_list():
nCoord = []
node_ids = cubit.get_entities("node")
for id in node_ids:
nCoord.append(cubit.get_nodal_coordinates(id))
return nCoord
Note-2:
Here the user was adding each element one-at-a-time. However, adding elements to blocks is an expensive operation. Therefore we recommend accumulating a list of the element ids to add to a block and then only add them to the block once you’ve finished accumulating the list.
- Add
list_to_str()helper function to convert a list of ids into a Cubit-compatible string of ids:def list_to_str(input_val): return " ".join([str(val) for val in input_val]) - Accumulate list of block hexes and move the block creation outside the loops:
block_hexes = [] for c_id in cell_list: #stuff for n_id in cubit.get_connectivity("hex", c_id): #stuff if cubit.body(bc_vol).point_containment([cxc,cyc,czc]): block_hexes.append(c_id) # <-- THIS LINE cubit.silent_cmd(f"block 1 hex {list_to_str(block_hexes)}") # <-- THIS LINE
Implementing Notes 1 and 2 results in a significant speedup: From 51 seconds to 2.3 seconds for 27K elements, and from several days to about 30 minutes on the 729K element mesh. This is still A) too long and B) still >20X fewer elements than our target (20M). This leads us to:
Note-3:
Something we noticed when digging around was that the API call to the point containment routine (i.e. cubit.body(bc_vol).point_containment()) was getting slower every call:
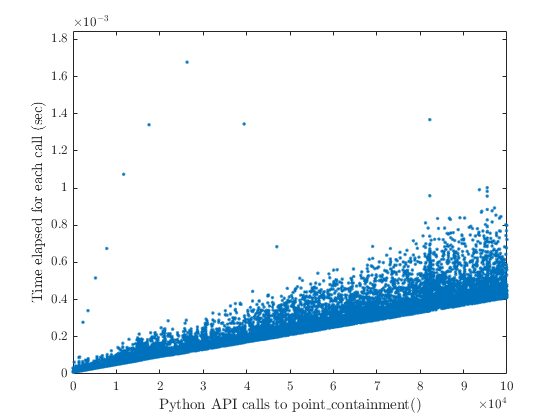
While we feel this is a bug, that we’re digging deeper into, this reminds me of a thing I learned during my Abaqus-user days: whenever possible, use as little nested object calls as possible. Essentially, I learned (in Abaqus) that:
## Bad Abaqus Script Example -- very slow
for i in range(0,num_elems):
elem_nodes = mdb.models['Model-1'].parts['Part-1'].elements[i].connectivity
## Good Abaqus Script Example -- very fast
elems = mdb.models['Model-1'].parts['Part-1'].elements
for i in range(0,num_elems):
elem_nodes = elems[i].connectivity
Applying this logic to this Cubit Python performance issue, we assign the body prior to the loop:
BODY = cubit.body(bc_vol) # <-- THIS LINE
block_hexes = []
for c_id in cell_list:
#stuff
for n_id in cubit.get_connectivity("hex", c_id):
#stuff
if BODY.point_containment([cxc,cyc,czc]):
# ^^^^^^^^^^^^ THIS LINE ^^^^^^^^^^^^ #
block_hexes.append(c_id)
cubit.silent_cmd(f"block 1 hex {list_to_str(block_hexes)}")
This has a dramatic effect and allows us to process 729K elements in 8 seconds and our 20M element target in 5 minutes – achieving our goal!
Solution:
After a bit more cleanup for readability (as determined by yours truly) the final working script is:
import time
def list_to_str(input_val):
return " ".join([str(val) for val in input_val])
def test_setup(refine_level):
cubit.cmd('reset')
cubit.cmd('create brick x 10')
cubit.cmd('create Cylinder height 3 radius 3 ')
cubit.cmd('mesh Volume 1')
if refine_level > 0:
cubit.cmd(f'refine hex all numsplit {refine_level} bias 1.0 depth 1 ')
cubit.cmd("compress")
def create_nodal_coordinates_array():
nCoord = []
node_ids = cubit.get_entities("node")
for id in node_ids:
nCoord.append(cubit.get_nodal_coordinates(id))
return nCoord
def get_hex_centroid(hex_id, global_node_coords):
hex_nodes = cubit.get_connectivity("hex", hex_id)
cx=cy=cz=0
count = 0
for node_id in hex_nodes:
cx += global_node_coords[node_id-1][0]
cy += global_node_coords[node_id-1][1]
cz += global_node_coords[node_id-1][2]
count += 1
cx = cx/count
cy = cy/count
cz = cz/count
return cx, cy, cz
def vol_hexes_in_body(source_volume_id, target_body_id):
BODY = cubit.body(target_body_id)
vol_hexes = cubit.get_volume_hexes(source_volume_id)
block_hexes = []
nCoord = create_nodal_coordinates_array()
for hex_id in vol_hexes:
cx, cy, cz = get_hex_centroid(hex_id, nCoord)
if BODY.point_containment([cx, cy, cz]):
block_hexes.append(hex_id)
cubit.silent_cmd(f"block 1 hex {list_to_str(block_hexes)}")
## Script body
test_setup(3)
vol_hexes_in_body(1, 2)
And for the ~20M element case (which is specified via test_setup(3), use a smaller integer for smaller mesh sizes if you’re interested) we get the following timing results:
Number of Elements: 19,683,000
Time to do fetch nodal coordinates array: 11 seconds
Time to do inside/outside test: 172 seconds
Time to add hexes to block: 66 seconds
Conclusions:
If your Python script seems slow, try the following:
- Avoid redundant calls to the Python API (see
Note-1) - Make sure you’re not (see
Note-2) - Try minimizing repeated calls into nested objects / functions (see
Note-3)# Change this for cid in range(0, num_curves): cubit.curve(cid).tangent(cubit.curve(cid).position_from_u(0.5)) # To this for cid in range(0, num_curves): C = cubit.curve(cid) C.tangent(C.position_from_u(0.5)) - Profile your code using
time.perf_counter()# Example import time t0 = time.perf_counter() cubit.cmd("block 1 hex all") t1 = time.perf_counter() print(f"Time to create block: {t1 - t0} seconds") - Check to see if there are any algorithmic improvements you can make (e.g. replace an \mathcal{O}(n^2) algorithms with \mathcal{O}(n), \mathcal{O}(n\log(n)), or \mathcal{O}(\log(n)) algorithm)
- Try installing NumPy, Pandas, SciPy, etc. and use their optimized datatypes and algorithms
- Post your script on our forum and a minimum working example!



